EMC3 Projects
Deep Codesign of Advanced Memory Technologies
Many of Los Alamos National Laboratory’s (LANL) High Performance Computing (HPC) codes are heavily memory bandwidth bound. These codes often exhibit high levels of sparse memory access which differ significantly from many HPC codes but share some similarity to other major market workloads such as graph analysis and sparse table joins in database applications.
Historically, the floating point operations per second (FLOPs) of a given architecture served as a reasonable proxy to total application performance in high performance computing (HPC). As FLOP instructions per cycle (IPC) has increased by orders of magnitude over that of memory IPC and as our HPC codes have grown increasingly complex with highly sparse data structures, this is no longer the case. In most respects, dense FLOPs are a solved problem and memory bandwidth for dense and, especially, sparse workloads is the primary performance challenge in HPC architecture. To address this challenge LANL is working on a number of technologies to better understand sparsity in our applications, potential hardware and software solutions, and how our applications may need to change to leverage these solutions. This deep codesign of complex applications and memory technologies is a primary focus area as we shape our next generation architectures.
* Shipman et.al., “The Future of HPC in Nuclear Security” , to appear in IEEE – Special Issue on the Future of HPC, 2023
Analysis shows that LANL applications are largely bottlenecked on the memory subsystem

Table: Architectural bottlenecks of applications of interest shows the memory subsystem (caches, memory transaction rate, bandwidth) is often a bottleneck in LANL applications. Floating point is rarely a bottleneck for any LANL applications.
To better understand this bottleneck we have developed a set of tools and techniques to characterize memory access. These techniques rely upon program instrumentation to capture memory access patterns. Examples of memory access patterns in our xRAGE and FLAG codes can be found here. https://github.com/lanl/spatter
These patterns can be used to drive system benchmarks using the Spatter tool https://hpcgarage.github.io/spatter/
Our tool to capture these patterns, known as gs_patterns is currently under release
Single-Node Weak Scaling (Solid=Gather, Dashed=Scatter): Spatter benchmark with FLAG memory access patterns
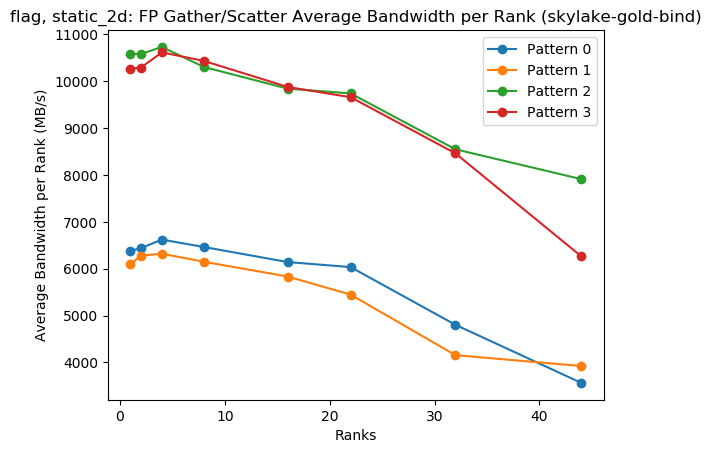
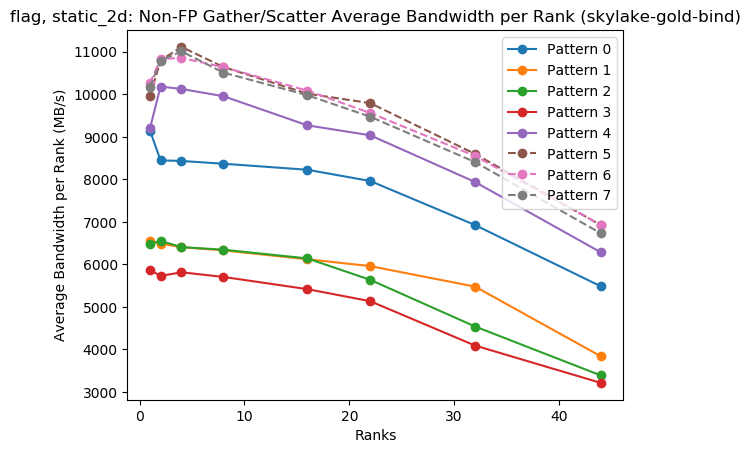
Spatter can be used to access current hardware technologies as well as future hardware (simulated) without relying upon full scale applications.
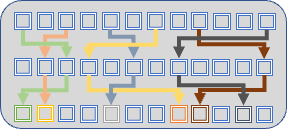
To obtain more detailed information on our application’s data structures and access patterns we have developed a complementary set of proxy applications. Previous physics “proxy” efforts revolved around creating simplified models of the entire application, but show very different memory access patterns than the original applications. We have developed EAP Patterns (EAP/AMR, Fortran) and UME (LAP/unstructured ALE, C++) extract a subset of the data structures and algorithms used in these applications, exposing the challenges of multi-level indirection, complex iteration patterns, and non-trivial data access mechanisms.
- UME focuses on a regional zone-gradient algorithm that is central to advection operations. This algorithm is applied to many fields in each of many material regions. Several mesh connectivity options are provided to allow exploration of the impact of connectivity on memory access patterns.
- EAP Patterns focuses on the cell gradients subroutine which is a face-based loop over a semi-structured AMR mesh (quad/oct-tree with minimum leaf chunk size of 2d)
- EAP Patterns: https://github.com/lanl/eap-patterns
- UME will be released shortly
These proxies illustrate the use of one and two levels of indirection as illustrated below.
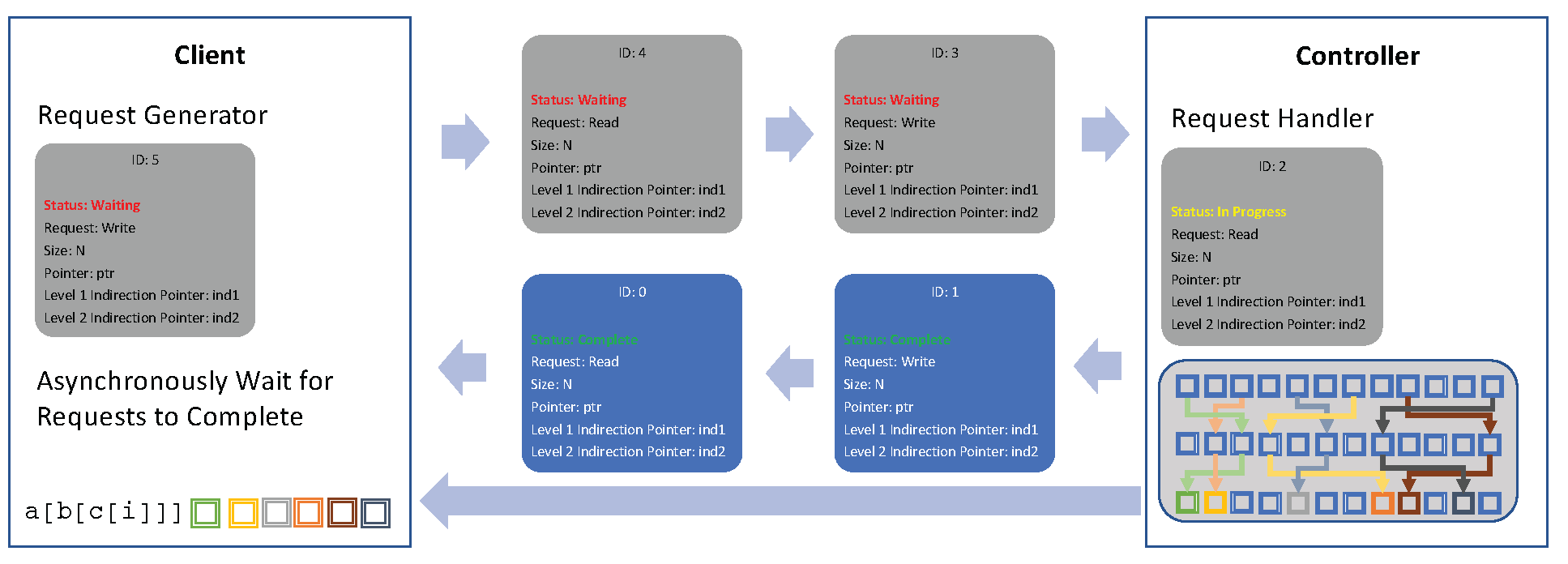
Our analysis of these indirect access patterns have led to the development of a prototype memory accelerator (software based) to explore how acceleration of indirect memory access could benefit our applications. Scoria (https://github.com/lanl/scoria) is our Sparse Memory Accelerator Prototype and is available as open source software.
-
-
- Goal: Prototype for evaluating sparse memory acceleration across hardware, approaches, and techniques
- Integrate with other micro-benchmarks and proxies for evaluation
- Client/Controller design to service sparse memory requests (0, 1, and 2 levels of indirection)
-