
EMC3 Projects
Grand Unified File Index (GUFI)
Existing metadata search solutions that provide low-latency, searchable indexes for data centers have two traditional problems: first, these systems do not enforce POSIX metadata permissions and second, the metadata search time is proportional to the total number of metadata entries indexed within the system. To provide a fast, secure metadata index that enables both users and administrators to efficiently search across all file systems within a data center we have developed the GUFI.
GUFI provides a single unified index for searching across multiple file systems. The index is constructed by scanning each of the file systems within the data center and creating a set of clustered databases that are sharded in a way that enforces standard POSIX file system permissions. Because GUFI strictly enforces POSIX metadata permissions it can be directly accessed by users and administrators. The index GUFI builds is used to accelerate interactive command line queries and as part of a web-based metadata search across an entire data center. Because the underlying index is stored in a set of embedded databases that each understand SQL, GUFI is able to support advanced query types that would be far too time-consuming with traditional metadata query tools. All of these capabilities are provided with transparent parallelism that is designed to achieve high levels of performance when accessing solid-state disks that store the index.
The essence of the design replicates the directory structure of the source tree with no files. In each index directory GUFI places an SQLite database that contains information about the directory and about the files within that directory. All the index trees from the different source file/storage systems are put together in a single search tree. The permissions of each database are set to be the same as the directory so that posix file metadata is protected exactly as in the source trees.
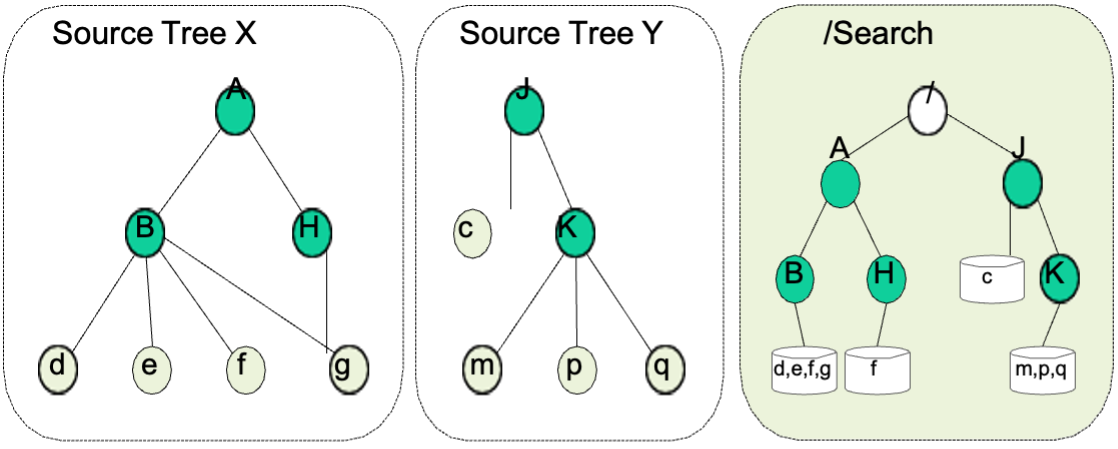
Because many subtrees have the same permissions in all directories below the top of the subtree. This allows us to “roll” that information up into the directory above which reduces the number of databases that need to be consulted by a query drastically while keeping the POSIX security intact.
Queries are just SQL queries that are distributed to many thread and these threads walk the index tree using breadth first search in parallel. Users with millions of files can find information in seconds and administrators can look at the entire set of billions of files in a few minutes maximum.
GUFI is open source and is available at https://github.com/mar-file-system/GUFI
Recent Supercomputing paper at https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10046106